ARQUITECTURA DE WINDOWS :
Este es el esquema de la arquitectura de windows.
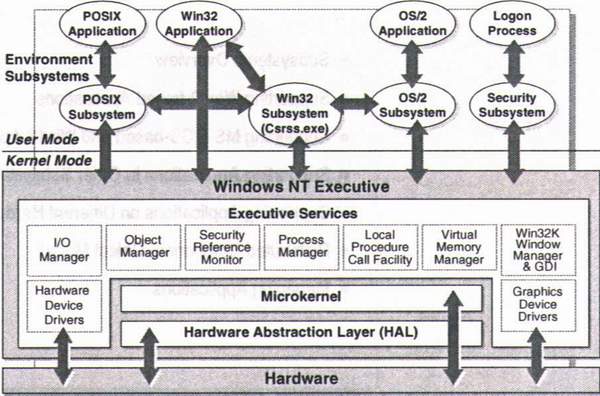
La cual está compuesta por una serie de componentes separados donde cada cual es responsable de sus funciones y brindan servicios a otros componentes. Esta arquitectura es del tipo cliente – servidor ya que los programas de aplicación son contemplados por el sistema operativo como si fueran clientes a los que hay que servir, y para lo cual viene equipado con distintas entidades servidoras.
Ya creado este diseño las demás versiones que le sucedieron a Windows NT fueron tomando esta arquitectura como base y le fueron adicionando nuevos componentes.
Uno de las características que Windows comparte con el resto de los Sistemas Operativos avanzados es la división de tareas del Sistema Operativo en múltiples categorías, las cuales están asociadas a los modos actuales soportados por los microprocesadores. Estos modos proporcionan a los programas que corren dentro de ellos diferentes niveles de privilegios para acceder al hardware o a otros programas que están corriendo en el sistema. Windows usa un modo privilegiado (Kernel) y un modo no privilegiado (Usuario).
Uno de los objetivos fundamentales del diseño fue el tener un núcleo tan pequeño como fuera posible, en el que estuvieran integrados módulos que dieran respuesta a aquellas llamadas al sistema que necesariamente se tuvieran que ejecutar en modo privilegiado (modo kernel). El resto de las llamadas se expulsarían del núcleo hacia otras entidades que se ejecutarían en modo no privilegiado (modo usuario), y de esta manera el núcleo resultaría una base compacta, robusta y estable.
El Modo Usuario es un modo menos privilegiado de funcionamiento, sin el acceso directo al hardware. El código que corre en este modo sólo actúa en su propio espacio de dirección. Este usa las APIs (System Application Program Interfaces) para pedir los servicios del sistema.
El Modo Kernel es un modo muy privilegiado de funcionamiento, donde el código tiene el acceso directo a todo el hardware y toda la memoria, incluso a los espacios de dirección de todos los procesos del modo usuario. La parte de WINDOWS que corre en el modo Kernel se llama Ejecutor de Windows, que no es más que un conjunto de servicios disponibles a todos los componentes del Sistema Operativo, donde cada grupo de servicios es manipulado por componentes que son totalmente independientes (entre ellos el Núcleo) entre sí y se comunican a través de interfaces bien definidas.
Todos los programas que no corren en Modo Kernel corren en Modo Usuario. La mayoría del código del Sistema Operativo corre en Modo Usuario, así como los subsistemas de ambiente (Win32 y POSIX que serán explicados en capítulos posteriores) y aplicaciones de usuario. Estos programas solamente acceden a su propio espacio de direcciones e interactúan con el resto del sistema a través de mensajes Cliente/Servidor.
ARQUITECTURA DE LINUX
La arquitectura interna de Linux es compleja pero se puede resumir las partes importántes de forma breve y fácil de entender.
PROCESOS
Linux se organiza en procesos, que son tareas independientes que se ejecutan de forma simultánea mientras el sistema está en funcionamiento. Los procesos cuelgan unos de otros en una dependencia padre/hijo. Inicialmente al arrancar el sistema sólo existe un proceso, llamado init. Init lee los ficheros de configuración de arranque presentes en el directorio /etc y va creando procesos hijos. Estos a su vez tendrán sus propios hijos formando un árbol de descendientes. Los procesos en ejecución se encuentran alojados en la memoria rápida RAM del sistema. Cuando se habla de ejecutar o lanzar o arrancar un proceso, nos estámos refiriendo al proceso de leer un fichero almacenado en el disco duro que contiene las instrucciones del programa, colocando las mismas en la memoria RAM y a continuación empezando a ejecutar las instrucciones del programa ya en RAM.
USUARIOS
Linux está diseñado para ser utilizado por varios usuarios simultáneamente. Aun cuando el sistema sólo vaya a ser utilizado por un único usuario, como es el caso corriente hoy en día, en general internamente Linux utilizará varios usuarios 'robots' para organizar mejor y de forma más segura el sistema. Linux siempre tiene un superusuario llamado 'root' ('raíz' traducido). En el siguiente párrafo se explica el por qué crea varios usuarios en vez de uno único.
Cada uno de los procesos pertenece a un usuario y en función del usuario asociado, dicho proceso tendrá unos permisos u otros. Un proceso en ejecución puede cambiar su usuario asociado si tiene los permisos suficientes para hacerlo. En general sólo tendrá permisos para cambiar de usuario cuando el usuario actual asociado al proceso sea 'root'. El proceso inicial Init se ejecuta con el usuario asociado 'root' lo cual le confiere permisos totales sobre la máquina. En general cuando Init ejecute sus procesos hijos lo hará asociandolos a usuarios distintos cuyos permisos se reduzcan a los esenciales para ejecutar la tarea para la cual están diseñado.
FICHEROS
Los procesos acceden al hardware y a otros recursos como la conexión de red a internet o los datos almacenados en disco a través de un sistema de ficheros. Todas las entradas y salidas de datos desde/hacia procesos se realiza a través de ficheros. P.ej, para acceder a la tarjeta gráfica de vídeo lo hará leyendo y escribiendo en:
/dev/video/card0
^ ^ ^
│ │ └── Tarjeta 0 (podría haber más de una tarjeta de video en el sistema)
│ │
│ └── Subdirectorio/carpeta video
│
└── Abreviatura de device (dispositivo)
Mientras que para acceder a un documento de texto almacenado en su disco duro lo hará accediento a una ruta similar a:
/home/usuario1/documento1.odf
^ ^ ^
│ │ └── Documento que queremos leer/editar.
│ │
│ └── Subdirectorio/carpeta usuario1 (puede haber muchos usuarios)
│
└── Directorio reservado para los ficheros de los usuarios finales
En general un mismo proceso puede acceder simultáneamente a varios ficheros y a su vez un mismo fichero puede ser accedido simultáneamente por varios procesos como se vé en el esquema siguiente:
ARBOL DE PROCESOS FICHEROS Y DIRECTORIOS
==========================================================================
procesoInicial(Init) /bin/Init
│
├── proc.Hijo1 ───────────────────▇───────────── /bin/proc.Hijo1
│ ├── proc.Hijo1.1 ──────────┼─▇─────────── /bin/proc.Hijo1.1
│ └── proc.Hijo1.2 ──────────┼─┼─▇───────── /bin/proc.Hijo1.2
├── proc.Hijo2 ───────────────────┼─┼─┼─▇─────── /bin/proc.Hijo2
│ ├── proc.Hijo2.1 ──────────┼─┼─┼─┼─▇───── /bin/proc.Hijo2.1
│ └── proc.Hijo2.2 ──────────┼─┼─┼─┼─┼─▇─── /bin/proc.Hijo2.2
├── proc.Hijo3 ───────────────────┼─┼─┼─┼─┼─┼─▇─ /bin/proc.Hijo3
│ └── proc.Hijo3.1 ──────────┼─┼─┼─┼─┼─┼─┼─ /bin/proc.Hijo3.1
│ └── proc.Hijo3.1.1┼─┼─┼─┼─┼─┼─┼─ /bin/proc.Hijo3.1.1
├── proc.Hijo4 │ │ │ │ │ │ │ ...
... ▇─▇─▇─▇─▇─▇─▇─ /
▇─▇─▇─┼─┼─┼─┼─ /dev/pts/0
┼─┼─┼─▇─▇─▇─┼─ /dev/pts/1
┼─┼─┼─┼─┼─┼─┼─ /dev/pts/2
┼─▇─┼─┼─▇─┼─┼─ /etc/passwd
┼─┼─▇─┼─┼─▇─┼─ /dev/snd/controlC0
▇─▇─▇─▇─▇─▇─▇─ /dev/null
▇─┼─▇─┼─▇─▇─▇─ /lib/i686/libc-2.11.so
...
En el esquema anterior puede verse como por ejemplo todos los procesos (lado izquierdo) tienen acceso a '/', la raíz del sistema así como a /dev/null. Cada proceso tiene acceso también a su imagen en el disco duro desde donde se leen el mismo antes de volcarla a memoria RAM.
A continuación se muestra un ejemplo real del árbol de procesos hasta llegar al proceso navegador firefox:
USUARIO PROCESO
root /sbin/init [5]
...
root \_ /usr/sbin/gdm-binary
usuario1 \_ /etc/X11/X
usuario1 \_ gnome-panel
usuario1 \_ /usr/bin/firefox
En el esquema anterior se puede observar como el proceso inicial init lanzará entre otros el proceso gdm-binary que es el encargado de autentificarnos con nuestro usuario y password. A continuación ejecutará el entorno gráfico X. Dentro de X se ejecutarán una serie de aplicaciones, p.ej, el relog mostrando la hora o el administrador de archivos. En el esquema anterior se muestra sólamente la aplicación gnome-panel, una pequeña barra colocada en el lateral del monitor y que sirve para que el usuario pueda indicarle al sistema qué otras tareas (procesos) quiere ejecutar a continuación pulsando sobre un icóno gráfico asociado a la misma. En este caso se ejecutó él navegador web firefox. Como puede observarse en el esquema firefox se ejecuta asociado al usuario1 y por tanto con los permisos restringidos del mismo ya que es hijo de gnome-panel que a su vez es hijo de X y que fué ejecutado como usuario1 por el gestor de sesiones una vez identificados correctamente con nuestro usuario y password. Si mientras navegamos por internet un virus se colase en nuestro navegador entonces el esquema anterior quedaría como:
USUARIO PROCESO
root /sbin/init [5]
...
root \_ /usr/sbin/gdm-binary
usuario1 \_ /etc/X11/X
usuario1 \_ gnome-panel
usuario1 \_ /usr/bin/firefox
usuario1 \_ /home/usuario1/MiVirusFavorito
MiVirusFavorito estaría muy limitado y sólo podría acceder a ficheros del usuario1, es decir aquellos situados dentro de la carpeta /home/usuario1/. Puesto que no tiene acceso a los ficheros de arranque si reiniciamos la máquina el virus morirá ya que 'init' jamás ejecutará el fichero /home/usuario1/MiVirusFavorito. Por otro lado puesto que otras máquinas sólo permanecerán infectadas mientras el virus esté en funcionamiento la posibilidad de que dicha máquina 'zoombie' nos ataque será muy reducida. Este sistema de seguridad no transforma a Linux en un sistema invencible pero sí mucho más complicado de infectar que otros sistemas operativos.






