sábado, 29 de octubre de 2011
lunes, 5 de septiembre de 2011
preguntas sobre la capa de red del modelo osi con única respuesta selección multiple.
1.¿ Las características de cada protocolo son?
A. Análogos
B. Diferentes
C. Homogéneas
D. Simétricos
2. ¿El protocolo ipv4, las características básicas son?
A. Rastrear información
B. Administrar el flujo de datos
C. Enviar un paquete desde un origen hacia un destino.
D. No establece conexión antes de enviar los paquetes de datos.
3. ¿El proceso de fragmentación de paquetes o fragmentación es?
A. El tamaño máximo de PDU. Que cada medio puede transportar
B. Control de enlace de datos.
C. Cuando un dispositivo intermediario o general y un router, necesita separar un paquete cuando se lo envía desde un medio a otro medio, con una MTU màs pequeña.
4¿los términos red y subred para que se utilizan?
A. Como protocolos
B. Para dividir la comunicación
C. Planear la comunicación entre hosts.
D. Para referirse a cualquier sistema de real hecho, posible por los protocolos de comunicación comunes compartidos del modelo TCP/IP
5. Las redes se puede agrupar factores que incluyen:
A. Función de los hosts
B. División de los hosts
C. Ubicación geográfica, propósito y propiedad
D. Diseños de comunicación
6. ¿Cuales son los problemas comunes con las redes grandes?
A. Velocidad de los hosts
B. División de La red
C. Degradación de rendimiento, seguridad y administración de dirección.
D. Grandes números de hosts, grandes volúmenes de tráfico de datos.
7. ¿Qué es un broadcast?
A. Es una red
B. Es una información
C. Transmisión de un paquete que será recibido por todos los dispositivos en una red.
D .Es un mensaje en la comunicación de la red.
8 ¿Los routers en una tabla de enrutamiento tienen 3 características principales cuales son?
A. Red de destino, próximo salto y métrica.
B. métrica, host, red.
C. Red de destino, enrutamiento y host de envió.
D. Paquete de comunicación, métrica, próximo salto.
9 el tiempo de vida (TTL) se define:
A. Como MTU pequeña
B. Tamaño máximo de PDU
C. un concepto usado en redes de computadores para indicar por cuántos nodos puede pasar un paquete antes de ser descartado por la red o devuelto a su origen.
D. El valor se vuelve cero
10 Una de las principales funciones de la capa de red es:
A. Aumentar el número de host en la web
B. Dividir los hosts de la red
C. Plantear los hosts
D. Es proveer un mecanismo para direccionar hosts
11 El término de host se define:
A. Servicio de protocolo
B. Conectar una red, que provee servicios interconectados con uno o más equipos.
C. Como protocolo ipv4
D.ipv6
12 Uno de los procesos básicos que realiza el transporte de extremo a extremo es:
A.ipv4
B.ipv6
C. Direccionamiento, encapsulación.
D. Host de transporte
13 El tema central del capitulo es:
A. Host
B. El protocolo ipv4 yipv6
C. El encapsulamiento
D. El dispositivo
14. La seguridad entre redes como se implementa:
A. El acceso a internet
B. Administración de la red
C. Implementada en un dispositivo intermediario (router o firewall) en el perímetro de la red.
D. enlaces de seguridad.
15. ¿cómo esta compuesta internet?
A. Por enlaces de seguridad
B. Por dispositivos
C. Por paquetes
D. compuesta por millones de host y cada uno se identifica con una dirección única en internet.
16. Para dividir redes se necesita:
A. Enlaces
B. Exclusividad de hosts
C. Direccionamiento jerárquico
D. paquetes de hosts
17 los gateways que función cumplen:
A. permiten las comunicaciones entre redes
B. Llevar datos de extremo a extremo,
C. Transportar hosts
D. Recibir hosts
18 ¿como se envía un paquete?
A .Por hosts
B Dispositivos.
C. Transporte de hosts.
D Envió con una ruta simple.
19 La ruta default es:
A. Es una ruta que coincide con todas las redes del destino.
B. Permite comunicación entre redes.
C. Un router configurado
D.ipv4
20. Entre los protocolos de enrutamiento comunes Se incluyen:
A. Router configurados
B. IPV4
C. Protocolo de información d e enrutamiento (RP)
D. enrutamiento estático

lunes, 18 de abril de 2011
¿De que esta compuesto el MBR?
En la práctica, el MBR casi siempre se refiere al sector de arranque de 512 bytes, o el partition sector de una partición para ordenadores compatibles con IBM PC. Debido a la amplia implementación de ordenadores PC clónicos, este tipo de MBR se usa mucho, hasta el punto de ser incorporado en otros tipos de ordenador y en nuevos estándares multiplataforma para el particionado y el arranque.
Cuando un dispositivo de almacenamiento de datos se ha particionado con un esquema de tabla de particiones del MBR (por ejemplo el esquema convencional de particionado de IBM PC), el MBR contiene las entradas primarias en la tabla de particiones. Las entradas de particiones secundarias se almacenan en registros de particiones extendidas, etiquetas de disco BSD, y particiones de metadatos del Logical Disk Manager que son descritas por esas entradas de particiones primarias.

Por convención, hay exactamente cuatro entradas de particiones primarias en el esquema de la Tabla de Particiones, aunque en algunos sistemas (pocos) se ha extendido ese número a cinco u ocho.
Cuando un dispositivo de almacenamiento de datos se ha particionado con Tabla de Particiones GUID, el Master Boot Record no contiene la tabla de particiones (aunque contiene modelos de estructuras de datos, una protección del MBR frente a programas que sólo entienden el esquema de la Tabla de Particiones del MBR para que no creen particiones en el disco) y se usa poco debido a lo que puede afectar al particionado de disco.
En linux.¿cual es la funcion de las particiones: /(raiz); /boot y swap?
/ (RAIZ)
Esta es la partición más importante. No solo contiene los datos más importantes para el sistema, sino que también oficiará de punto de montaje para otras particiones. Las necesidades para la partición raíz en términos de tamaño son muy limitadas, 300MB es suficiente. Sin embargo, si planea instalar aplicaciones comerciales, que generalmente residen en /opt, necesitará incrementar dicho tamaño. Otra opción es crear una partición separada para /opt.
/BOOT
crea arranques del sistema.
SWAP
no es más que un espacio en el disco duro (una partición, aunque también puede ser un archivo) que actúa como si fuera memoria RAM, pero es bastante más lenta, claro está. También se le denomina memoria virtual, y Linux no es el único sistema operativo o, mejor dicho, núcleo, que hace uso de esta técnica. No vamos a entrar en detalles sobre su funcionamiento, pero podemos decir, a modo de ayuda para formarse una idea, que cuando el sistema necesita más memoria libre de la que tiene disponible, guarda unos cuantos datos en el espacio swap del disco y utiliza el que ocupaban en la RAM, volviendo a recuperar los datos guardados cuando los necesite, aún a costa de sustituirlos por otros. Si tuviésemos realmente muy poca memoria RAM la lentitud del sistema puede llegar a ser exasperante, o incluso algo más.

cuales son los tipos de archivos admitidos para: DOS, windows 95, windows 98, windows xp, windows 7, linux, macOS, OS/2, sun solaris e IBM AIX.
Como sabemos que cada sistema operativo maneja diferentes sistemas de archivo podrán ver en la siguiente tabla el sistema de archivo que admite cada sistema operativo:
Sistema operativo | Tipos de sistemas de archivos admitidos |
Dos | FAT16 |
Windows 95 | FAT16 |
Windows95 OSR2 | FAT16, FAT32 |
Windows 98 | FAT16, FAT32 |
Windows NT4 | FAT, NTFS (versión 4) |
Windows 2000/XP | FAT, FAT16, FAT32, NTFS (versiones 4 y 5) |
Linux | Ext2, Ext3, ReiserFS, Linux Swap (FAT16, FAT32, NTFS) |
MacOS | HFS (Sistema de Archivos Jerárquico), MFS (Sistemas de Archivos Macintosh) |
OS/2 | HPFS (Sistema de Archivos de Alto Rendimiento) |
SGI IRIX | XFS |
FreeBSD, OpenBSD | UFS (Sistema de Archivos Unix) |
Sun Solaris | UFS (Sistema de Archivos Unix) |
IBM AIX | JFS (Sistema Diario de Archivos) |
Coexistencia de varios sistemas de archivos
Cuando coexisten varios sistemas operativos en la misma máquina, la elección de un sistema de archivos es un gran problema. Debido a que el sistema de archivos está estrechamente ligado al sistema operativo, cuando existen varios sistemas operativos, usted debe elegir un sistema de archivos para cada uno, teniendo en cuenta que es posible que deba acceder a los datos de un sistema operativo desde otro. Una solución sería la de usar particiones FAT para todos los sistemas, asegurándose de que las particiones no sean mayores a 2 GB. La solución más apropiada sería la de utilizar, para cada SO, una partición cuyo sistema de archivos sea el que mejor se adapte a ésta y utilizar una partición FAT16 dedicada para que los diferentes sistemas operativos compartan datos.
Por que linux es llamado GNU/linux
El nombre GNU, GNU's Not Unix (GNU no es Unix), viene de las herramientas básicas de sistema operativo creadas por el proyecto GNU, iniciado por Richard Stallman en 1983 y mantenido por la FSF. El nombre Linux viene del núcleo Linux, inicialmente escrito por Linus Torvalds en 1991.
La contribución de GNU es la razón por la que existe controversia a la hora de utilizar Linux o GNU/Linux para referirse al sistema operativo formado por las herramientas de GNU y el núcleo Linux en su conjunto.
CUAL ES LA DIFERENCIA ENTRE UN SOFTWARE DE DOMINIO PUBLICO , SOFTWARE GRATUITO Y SOFTWARE LIBRE
SOFTWARE DE DOMINIO PUBLICO Y SOFTWARE GRATUITO.
El software de dominio público no está protegido por las leyes de derechos de autor y puede ser copiado por cualquiera sin costo alguno. Algunas veces los programadores crean un programa y lo donan para su utilización por parte del público en general. Lo anterior no quiere decir que en algún momento un usuario lo pueda copiar, modificar y distribuir como si fuera software propietario. Así mismo, existe software gratis protegido por leyes de derechos de autor que permite al usuario publicar versiones modificadas como si fueran propiedad de este último.
SOFTWARE LIBRE.
“Software Libre” se refiere a la libertad de los usuarios para ejecutar, copiar, distribuir, estudiar, cambiar
y mejorar el software. De modo más preciso, se refiere a cuatro libertades de los usuarios del software:
• La libertad de usar el programa, con cualquier propósito (libertad 0).
• La libertad de estudiar cómo funciona el programa, y adaptarlo a tus necesidades (libertad 1). El acceso al
código fuente es una condición previa para esto.
• La libertad de distribuir copias, con lo que puedes ayudar a tu vecino (libertad 2).
• La libertad de mejorar el programa y hacer públicas las mejoras a los demás, de modo que toda la comunidad
se beneficie. (libertad 3). El acceso al código fuente es un requisito previo para esto.
Un programa es software libre si los usuarios tienen todas estas libertades. Así pues, deberías tener la
libertad de distribuir copias, sea con o sin modificaciones, sea gratis o cobrando una cantidad por la distribución,
a cualquiera y a cualquier lugar. El ser libre de hacer esto significa (entre otras cosas) que no tienes que
pedir o pagar permisos.
También deberías tener la libertad de hacer modificaciones y utilizarlas de manera privada en tu trabajo
u ocio, sin ni siquiera tener que anunciar que dichas modificaciones existen. Si publicas tus cambios, no tienes
por qué avisar a nadie en particular, ni de ninguna manera en particular.CONCLUSIÓN
Un software libre es aquel programa que puede ser ejecutado, estudiado,copiado y adaptado a las necesidades de un usuario sin que éste tenga que pedir algún permiso.
un software de dominio publico es aquel programa que no esta protegido por la ley de derechos de autor pero que puede ser copiado sin ningún costo y por ultimo un software gratuito es aquel programa que bajo la ley de derechos de autor el usuario puede modificar y publicar como si fuera suyo.
Cual es la diferencia entre GNU Hurd y GNU Mach
GNU Hurd
- Es un conjunto de programas servidores que simulan un núcleo Unix que establece la base del sistema operativo GNU.
- Hurd intenta superar los núcleos tipo Unix en cuanto a funcionalidad, seguridad y estabilidad, aun manteniéndose compatible con ellos. Esto se logra gracias a que Hurd implementa la especificación POSIX (entre otras), pero eliminando las restricciones arbitrarias a los usuarios.
GNU Mach
- Es el micronúcleo oficial del Proyecto GNU. Como cualquier otro micronúcleo, su función principal es realizar labores mínimas de administración sobre el hardware para que el grueso del sistema operativo sea operado desde el espacio del usuario.
- En la actualidad el GNU Mach sólo funciona en máquinas de arquitectura Intel de 32 bits y su uso más popular es servir de soporte a Hurd, el proyecto que pretende reemplazar a los núcleo tipo Unix en el sistema operativo libre GNU.
VULNERABILIDAD DE WINDOWS VISTA
La vulnerabilidad se encuentra en el sistema de red cuando se envían solicitudes a la API “iphlpapi.dll”. El error está comprobado en Vista Ultimate y Enterprise y según los investigadores “es muy probable que afecte al resto de versiones de 32 y 64 bits”. Windows Xp no está afectado, según explican.
El exploit puede ser usado para apagar la computadora o provocar la pérdida de conectividad de la Red usando ataques de denegación de servicio (DoS). Aunque se necesitan permisos de administrador para aprovechar la vulnerabilidad, la misma podría ser explotada mediante envío de paquetes DHCP sin permisos de administración, según explican desde el grupo de seguridad austriaco, que informó que llevaban trabajando desde el mes pasado con responsables del “Microsoft Security Response Center” para “ubicar, clasificar y corregir la vulnerabilidad”.
"Min Win" EL NUCLEO DE WINDOWS 7
Min Win consiste en coger el núcleo de Windows e ir quitando cosas y parar sólo justo antes de que deje de funcionar. ¿Cuál era el objetivo? Simplemente consolidar el diseño del núcleo del sistema operativo. Por lo visto los ingenieros de Microsoft descubrieron que los sistemas de bajo nivel del núcleo de Windows realizaban llamadas a procesos de alto nivel.

Para mejorar el diseño “cortaron” estas llamadas de alto nivel para convertir el núcleo de Windows en un sistema escalable. De esta manera se realizó un mapa de dependencias para poder limpiar las llamadas que se realizaban fuera del núcleo. Se reorgnizaron estas llamadas y las API. El experimento acabó con un sistema operativo que funcionaba perfectamente sin necesidad de librerías de alto nivel: el MinWin. El sistema ocupa de 25 a 40 Megabytes, frente a los 4 Gigabytes de Vista, y se compone de apenas 100 ficheros, cuando Windows necesita 5.000 para funcionar.
De esta forma se creó un “corazón” de Windows nuevo autocontenido y escalable, pero que contiene el núcleo (el kernel) del Windows de toda la vida, sólo que con las llamadas de alto nivel y las API reorganizadas. La clave es, según el propio Russinovich, en la diferencia entre “Core” y “kernel”. El kernel o núcleo de Windows 7 es el mismo de siempre, pero el core (el corazón) ha cambiado, se ha reorganizado. Así que MinWin no es un nuevo kernel, sino un kernel reorganizado. ¿Por qué se ha hecho de esta manera? En primer lugar porque es mucho menos costoso reorganizar y optimizar el núcleo de Windows que empezar desde cero. Por el otro se conserva la compatibilidad con el sistema anterior, porque todas las llamadas se realizan de la misma forma y el núcleo funciona de la misma manera.
COMPARACIÓN DEL NÚCLEO DE WINDOWS Y EL NÚCLEO DE LINUX
Algunos aspectos a tener en cuenta son:
- llamadas del sistema (system calls), mientras Linux tiene 320 Windows tiene más de 1000. A simple vista no se puede sólo por el dato comparar si esto es mejor para uno u otro, pero el hecho de que los desarrolladores no se suelan quejar de las llamadas del sistema en Linux me hace pensar que “tienen lo que necesitan”. Si estoy en lo cierto, el número abultado de llamadas en el kernel de Windows debe ser por mantener la (arcaica) compatibilidad hacía atrás lo cual como ya he dicho en anteriores veces vuelve el diseño muy complejo y propenso a errores.
- el tiempo de desarrollo, cada “versión menor” (en el caso de linux los 2.6.x) dura 3 meses en linux y 31 en Windows. En las versiones mayores la cosa ya se balancea menos: Linux tarda 35 meses y Windows 38.
- El tamaño resultante del kernel (sin drivers/módulos) también es exageradamente, Linux ocupa 1.3MB frente a los 4.6MB de Windows.
- el número de arquitecturas soportadas donde Windows literalmente es machado: Windows soporta x86 (los ordenadores de toda la vida), AMD64 y IA-64. Linux soporta ésas y además otras 14 arquitecturas sin contar consolas.
- El tamaño en líneas de código en Windows aumenta en cada versión (actualmente 10 millones de líneas) de forma exagerada aunque Linux en cada versión mete soporte para mucho hardware sin que aumente el número tanto (4 millones actualmente) osea que no sé que pensar. El número anterior es sin drivers, si incluimos los drivers los números se disparan y la diferencia también (Windows 25 millones, Linux 8).

NOMENCLATURA DE KERNEL
La nomenclatura del Kernel se divide en 3 campos separados por un punto (.), estos son:
Primer campo: Número de la versión, actualmente a fecha de este documento es la 2.
Segundo campo: Numero de "sub-versión", por llamarlo de algun modo, es la version dentro de la propia versión, si este numero es par, la versión sera estable, si por el contrario es impar, ésta sera inestable.
Tercer campo: Nivel de corrección el en que se encuentra.
Primer campo: Número de la versión, actualmente a fecha de este documento es la 2.
Segundo campo: Numero de "sub-versión", por llamarlo de algun modo, es la version dentro de la propia versión, si este numero es par, la versión sera estable, si por el contrario es impar, ésta sera inestable.
Tercer campo: Nivel de corrección el en que se encuentra.
ARQUITECTURA DE WINDOWS Y LINUX
ARQUITECTURA DE WINDOWS :
Este es el esquema de la arquitectura de windows.
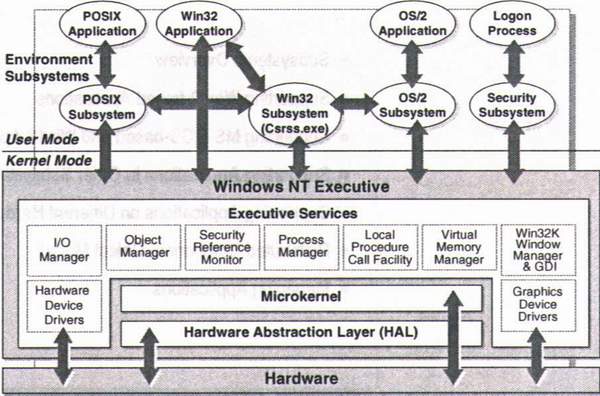
Este es el esquema de la arquitectura de windows.
La cual está compuesta por una serie de componentes separados donde cada cual es responsable de sus funciones y brindan servicios a otros componentes. Esta arquitectura es del tipo cliente – servidor ya que los programas de aplicación son contemplados por el sistema operativo como si fueran clientes a los que hay que servir, y para lo cual viene equipado con distintas entidades servidoras.
Ya creado este diseño las demás versiones que le sucedieron a Windows NT fueron tomando esta arquitectura como base y le fueron adicionando nuevos componentes.
Uno de las características que Windows comparte con el resto de los Sistemas Operativos avanzados es la división de tareas del Sistema Operativo en múltiples categorías, las cuales están asociadas a los modos actuales soportados por los microprocesadores. Estos modos proporcionan a los programas que corren dentro de ellos diferentes niveles de privilegios para acceder al hardware o a otros programas que están corriendo en el sistema. Windows usa un modo privilegiado (Kernel) y un modo no privilegiado (Usuario).
Uno de los objetivos fundamentales del diseño fue el tener un núcleo tan pequeño como fuera posible, en el que estuvieran integrados módulos que dieran respuesta a aquellas llamadas al sistema que necesariamente se tuvieran que ejecutar en modo privilegiado (modo kernel). El resto de las llamadas se expulsarían del núcleo hacia otras entidades que se ejecutarían en modo no privilegiado (modo usuario), y de esta manera el núcleo resultaría una base compacta, robusta y estable.
El Modo Usuario es un modo menos privilegiado de funcionamiento, sin el acceso directo al hardware. El código que corre en este modo sólo actúa en su propio espacio de dirección. Este usa las APIs (System Application Program Interfaces) para pedir los servicios del sistema.
El Modo Kernel es un modo muy privilegiado de funcionamiento, donde el código tiene el acceso directo a todo el hardware y toda la memoria, incluso a los espacios de dirección de todos los procesos del modo usuario. La parte de WINDOWS que corre en el modo Kernel se llama Ejecutor de Windows, que no es más que un conjunto de servicios disponibles a todos los componentes del Sistema Operativo, donde cada grupo de servicios es manipulado por componentes que son totalmente independientes (entre ellos el Núcleo) entre sí y se comunican a través de interfaces bien definidas.
Todos los programas que no corren en Modo Kernel corren en Modo Usuario. La mayoría del código del Sistema Operativo corre en Modo Usuario, así como los subsistemas de ambiente (Win32 y POSIX que serán explicados en capítulos posteriores) y aplicaciones de usuario. Estos programas solamente acceden a su propio espacio de direcciones e interactúan con el resto del sistema a través de mensajes Cliente/Servidor.
ARQUITECTURA DE LINUX
La arquitectura interna de Linux es compleja pero se puede resumir las partes importántes de forma breve y fácil de entender.
PROCESOS
Linux se organiza en procesos, que son tareas independientes que se ejecutan de forma simultánea mientras el sistema está en funcionamiento. Los procesos cuelgan unos de otros en una dependencia padre/hijo. Inicialmente al arrancar el sistema sólo existe un proceso, llamado init. Init lee los ficheros de configuración de arranque presentes en el directorio /etc y va creando procesos hijos. Estos a su vez tendrán sus propios hijos formando un árbol de descendientes. Los procesos en ejecución se encuentran alojados en la memoria rápida RAM del sistema. Cuando se habla de ejecutar o lanzar o arrancar un proceso, nos estámos refiriendo al proceso de leer un fichero almacenado en el disco duro que contiene las instrucciones del programa, colocando las mismas en la memoria RAM y a continuación empezando a ejecutar las instrucciones del programa ya en RAM.
USUARIOS
Linux está diseñado para ser utilizado por varios usuarios simultáneamente. Aun cuando el sistema sólo vaya a ser utilizado por un único usuario, como es el caso corriente hoy en día, en general internamente Linux utilizará varios usuarios 'robots' para organizar mejor y de forma más segura el sistema. Linux siempre tiene un superusuario llamado 'root' ('raíz' traducido). En el siguiente párrafo se explica el por qué crea varios usuarios en vez de uno único.
Cada uno de los procesos pertenece a un usuario y en función del usuario asociado, dicho proceso tendrá unos permisos u otros. Un proceso en ejecución puede cambiar su usuario asociado si tiene los permisos suficientes para hacerlo. En general sólo tendrá permisos para cambiar de usuario cuando el usuario actual asociado al proceso sea 'root'. El proceso inicial Init se ejecuta con el usuario asociado 'root' lo cual le confiere permisos totales sobre la máquina. En general cuando Init ejecute sus procesos hijos lo hará asociandolos a usuarios distintos cuyos permisos se reduzcan a los esenciales para ejecutar la tarea para la cual están diseñado.
FICHEROS
Los procesos acceden al hardware y a otros recursos como la conexión de red a internet o los datos almacenados en disco a través de un sistema de ficheros. Todas las entradas y salidas de datos desde/hacia procesos se realiza a través de ficheros. P.ej, para acceder a la tarjeta gráfica de vídeo lo hará leyendo y escribiendo en:
/dev/video/card0
^ ^ ^
│ │ └── Tarjeta 0 (podría haber más de una tarjeta de video en el sistema)
│ │
│ └── Subdirectorio/carpeta video
│
└── Abreviatura de device (dispositivo)
Mientras que para acceder a un documento de texto almacenado en su disco duro lo hará accediento a una ruta similar a:
/home/usuario1/documento1.odf
^ ^ ^
│ │ └── Documento que queremos leer/editar.
│ │
│ └── Subdirectorio/carpeta usuario1 (puede haber muchos usuarios)
│
└── Directorio reservado para los ficheros de los usuarios finales
En general un mismo proceso puede acceder simultáneamente a varios ficheros y a su vez un mismo fichero puede ser accedido simultáneamente por varios procesos como se vé en el esquema siguiente:
ARBOL DE PROCESOS FICHEROS Y DIRECTORIOS
==========================================================================
procesoInicial(Init) /bin/Init
│
├── proc.Hijo1 ───────────────────▇───────────── /bin/proc.Hijo1
│ ├── proc.Hijo1.1 ──────────┼─▇─────────── /bin/proc.Hijo1.1
│ └── proc.Hijo1.2 ──────────┼─┼─▇───────── /bin/proc.Hijo1.2
├── proc.Hijo2 ───────────────────┼─┼─┼─▇─────── /bin/proc.Hijo2
│ ├── proc.Hijo2.1 ──────────┼─┼─┼─┼─▇───── /bin/proc.Hijo2.1
│ └── proc.Hijo2.2 ──────────┼─┼─┼─┼─┼─▇─── /bin/proc.Hijo2.2
├── proc.Hijo3 ───────────────────┼─┼─┼─┼─┼─┼─▇─ /bin/proc.Hijo3
│ └── proc.Hijo3.1 ──────────┼─┼─┼─┼─┼─┼─┼─ /bin/proc.Hijo3.1
│ └── proc.Hijo3.1.1┼─┼─┼─┼─┼─┼─┼─ /bin/proc.Hijo3.1.1
├── proc.Hijo4 │ │ │ │ │ │ │ ...
... ▇─▇─▇─▇─▇─▇─▇─ /
▇─▇─▇─┼─┼─┼─┼─ /dev/pts/0
┼─┼─┼─▇─▇─▇─┼─ /dev/pts/1
┼─┼─┼─┼─┼─┼─┼─ /dev/pts/2
┼─▇─┼─┼─▇─┼─┼─ /etc/passwd
┼─┼─▇─┼─┼─▇─┼─ /dev/snd/controlC0
▇─▇─▇─▇─▇─▇─▇─ /dev/null
▇─┼─▇─┼─▇─▇─▇─ /lib/i686/libc-2.11.so
...
En el esquema anterior puede verse como por ejemplo todos los procesos (lado izquierdo) tienen acceso a '/', la raíz del sistema así como a /dev/null. Cada proceso tiene acceso también a su imagen en el disco duro desde donde se leen el mismo antes de volcarla a memoria RAM.
A continuación se muestra un ejemplo real del árbol de procesos hasta llegar al proceso navegador firefox:
USUARIO PROCESO
root /sbin/init [5]
...
root \_ /usr/sbin/gdm-binary
usuario1 \_ /etc/X11/X
usuario1 \_ gnome-panel
usuario1 \_ /usr/bin/firefox
En el esquema anterior se puede observar como el proceso inicial init lanzará entre otros el proceso gdm-binary que es el encargado de autentificarnos con nuestro usuario y password. A continuación ejecutará el entorno gráfico X. Dentro de X se ejecutarán una serie de aplicaciones, p.ej, el relog mostrando la hora o el administrador de archivos. En el esquema anterior se muestra sólamente la aplicación gnome-panel, una pequeña barra colocada en el lateral del monitor y que sirve para que el usuario pueda indicarle al sistema qué otras tareas (procesos) quiere ejecutar a continuación pulsando sobre un icóno gráfico asociado a la misma. En este caso se ejecutó él navegador web firefox. Como puede observarse en el esquema firefox se ejecuta asociado al usuario1 y por tanto con los permisos restringidos del mismo ya que es hijo de gnome-panel que a su vez es hijo de X y que fué ejecutado como usuario1 por el gestor de sesiones una vez identificados correctamente con nuestro usuario y password. Si mientras navegamos por internet un virus se colase en nuestro navegador entonces el esquema anterior quedaría como:
USUARIO PROCESO
root /sbin/init [5]
...
root \_ /usr/sbin/gdm-binary
usuario1 \_ /etc/X11/X
usuario1 \_ gnome-panel
usuario1 \_ /usr/bin/firefox
usuario1 \_ /home/usuario1/MiVirusFavorito
MiVirusFavorito estaría muy limitado y sólo podría acceder a ficheros del usuario1, es decir aquellos situados dentro de la carpeta /home/usuario1/. Puesto que no tiene acceso a los ficheros de arranque si reiniciamos la máquina el virus morirá ya que 'init' jamás ejecutará el fichero /home/usuario1/MiVirusFavorito. Por otro lado puesto que otras máquinas sólo permanecerán infectadas mientras el virus esté en funcionamiento la posibilidad de que dicha máquina 'zoombie' nos ataque será muy reducida. Este sistema de seguridad no transforma a Linux en un sistema invencible pero sí mucho más complicado de infectar que otros sistemas operativos.
Suscribirse a:
Entradas (Atom)